- 593
RAG Context-Aware Chunking: Google Drive to Pinecone via OpenRouter & Gemini
Enhance workflows by connecting Google Drive to Pinecone. Automate with OpenRouter and Gemini for efficient context-aware chunking.
Enhance workflows by connecting Google Drive to Pinecone. Automate with OpenRouter and Gemini for efficient context-aware chunking.
Who is this workflow for? This workflow automates the extraction, processing, and storage of document content from Google Drive into a Pinecone vector store using context-aware chunking. By leveraging tools like OpenRouter and Gemini, it enhances the accuracy of Retrieval-Augmented Generation (RAG) systems through meaningful context retention in each data chunk..
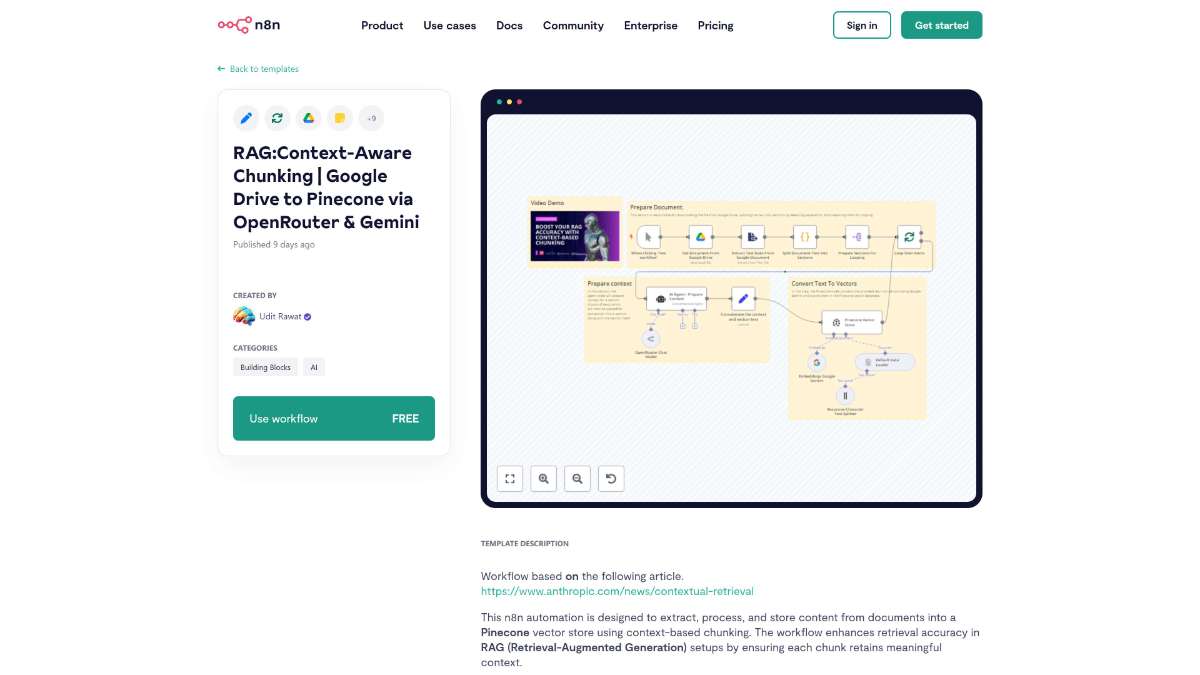
This workflow is ideal for data engineers, AI developers, and knowledge management professionals who need to efficiently manage and utilize large volumes of document data for advanced AI applications, particularly those involving retrieval-augmented generation.
This n8n workflow automates the seamless extraction, processing, and storage of document content from Google Drive into Pinecone using context-aware chunking. By integrating advanced AI models and various tools, it enhances the accuracy and efficiency of Retrieval-Augmented Generation systems, making it a valuable asset for managing and utilizing large sets of document data effectively.
Streamline your workflow by automating Strava updates and tweets. Save time with real-time activity syncing and seamless social media integration.
Streamline your workflow by importing and mapping credentials using a multi-form. Enhance efficiency and integration in your n8n processes.
Simplify your workflow by automating row creation in Grist. Harness n8n's power for seamless integration and efficient data management.
Help us find the best n8n templates
A curated directory of the best n8n templates for workflow automations.