- 693
Extract Text from PDF Files Using n8n Workflow
Automate text extraction from PDFs with n8n. Save time and streamline data processing using this powerful and flexible workflow solution.
Automate text extraction from PDFs with n8n. Save time and streamline data processing using this powerful and flexible workflow solution.
Who is this workflow for? This workflow automates the extraction of text from PDF files using n8n. By integrating various nodes, it seamlessly processes incoming PDF documents, retrieves their textual content, and makes the data available for further use or analysis..
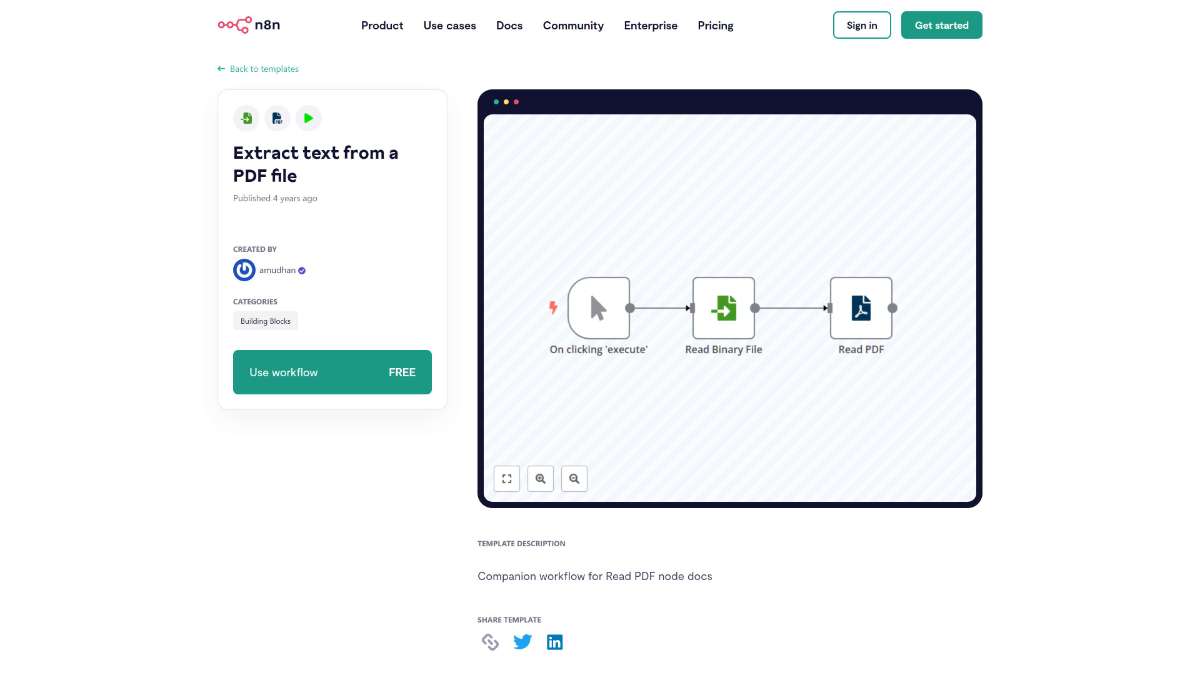
This workflow is ideal for:
This n8n workflow provides a comprehensive solution for extracting text from PDF files, integrating multiple services to automate and streamline the process. Whether for archiving, customer support, or content publishing, this workflow enhances efficiency and scalability in handling PDF documents.
Streamline data handling and automate workflows. Utilize n8n's powerful features to efficiently read and process spreadsheet files.
Automate exporting WordPress posts to spreadsheets. Save time with seamless integration and efficient data management using this n8n template.
Streamline ticket management by posting unassigned Zendesk tickets to Slack. Automate notifications and improve team collaboration with this n8n template.
Help us find the best n8n templates
A curated directory of the best n8n templates for workflow automations.