- 883
Create an AI Chatbot for Document Interaction in Supabase
Build a chatbot to enhance document interaction using AI; features include seamless integration with Supabase and efficient data handling.
Build a chatbot to enhance document interaction using AI; features include seamless integration with Supabase and efficient data handling.
Who is this workflow for? This workflow enables seamless interaction with your documents stored in Supabase through an AI-driven chatbot. By automating the processing, vectorization, and querying of text and PDF files, it allows for efficient retrieval of contextual information using natural language conversations..
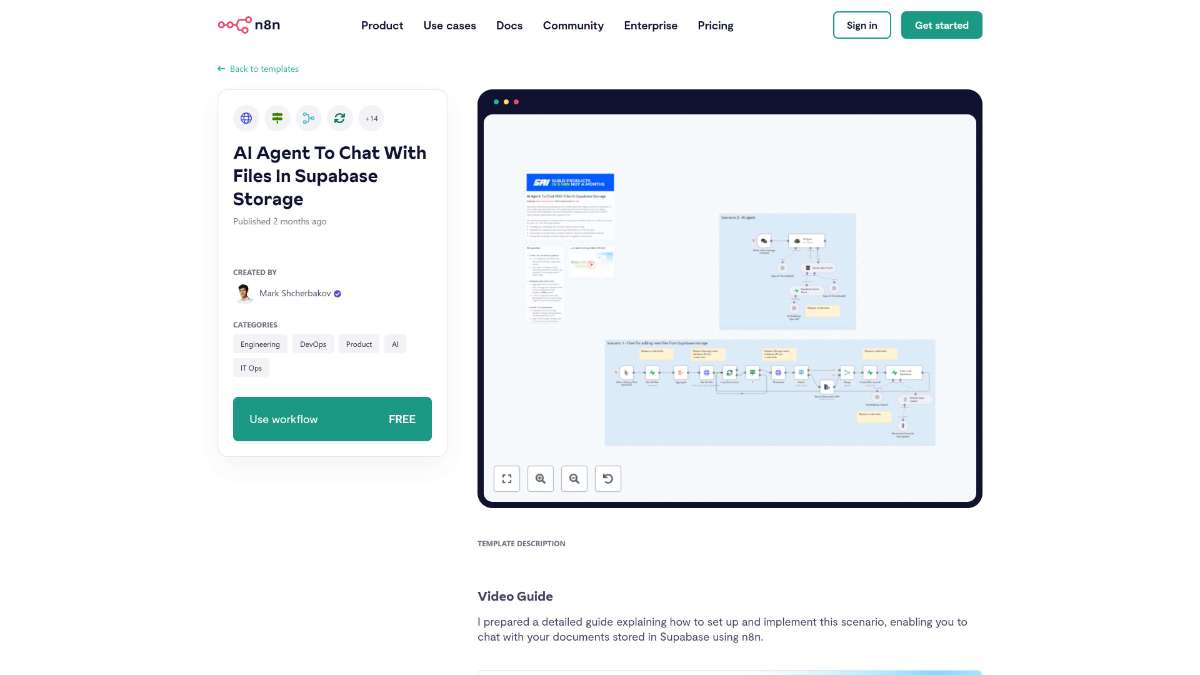
files table.This workflow is ideal for researchers, analysts, business owners, educators, and anyone managing a significant collection of documents. It is particularly beneficial for individuals who require quick access to specific information within text-heavy files stored in Supabase.
This workflow integrates Supabase with an AI-powered chatbot to efficiently process, store, and query your text and PDF files. By automating file handling, vectorization, and conversational querying, it provides a robust solution for quick and contextually relevant information retrieval from your document repository.
Streamline data analysis by integrating AI with Baserow. Enjoy automated SERP insights and efficient workflows with this n8n template.
Discover how to automate tasks using a Telegram bot with n8n. Enjoy seamless integration and easy setup with this comprehensive guide.
Streamline podcast summaries effortlessly with automated processing and daily updates using key n8n features.
Help us find the best n8n templates
A curated directory of the best n8n templates for workflow automations.