- 868
Automated System for Scraping and Storing Data from Websites
Extract and store data efficiently with this n8n template, featuring automated multi-page scraping and seamless data integration.
Extract and store data efficiently with this n8n template, featuring automated multi-page scraping and seamless data integration.
Who is this workflow for? This workflow automates the extraction and storage of data from multiple website pages, streamlining the process of gathering structured information across various countries. Leveraging n8n, it efficiently navigates through country-specific pages, handles pagination, and ensures data integrity by storing results in MongoDB..
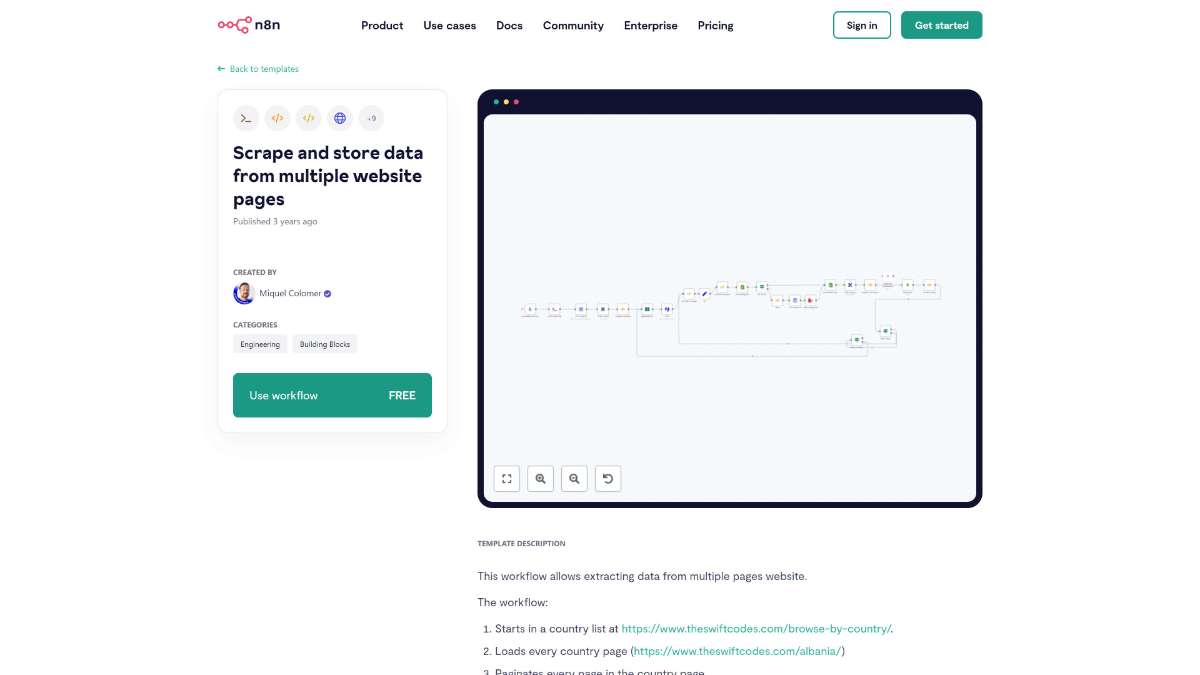
swift_code, which serves as the primary key.This workflow is ideal for data analysts, researchers, and developers who need to collect and manage large sets of data from structured websites. It is particularly beneficial for those who require regular updates from web sources without manual intervention.
This n8n workflow provides a robust solution for efficiently scraping and storing data from multiple website pages. By automating the navigation, extraction, and storage processes, it saves time and ensures data accuracy. With built-in caching, proxy support, and duplication checks, it offers a reliable framework for handling extensive data scraping tasks.
Enhance decision-making with AI. Automate insights, track performance, and optimize Meta ads efficiently in one streamlined workflow.
Overcome Telegram API limits by automating bulk messaging with this n8n template. Enhance efficiency and control message distribution seamlessly.
Streamline your workflow by automating Strava updates and tweets. Save time with real-time activity syncing and seamless social media integration.
Help us find the best n8n templates
A curated directory of the best n8n templates for workflow automations.